DUT人工智能与专家系统_HW1
1 采用广度优先搜索(BFS)、深度优先搜索(DFS)编程求解八数码问题(初始状态允许任意),找出一种从初始状态到目标状态移动步数最少的步骤。
八数码难题是一种经典的拼图游戏,也称为九宫格问题。它的目标是将一个 3x3 的方格拼图按照指定的顺序排列。每个方格上都有一个数字,其中一个方格为空,可以与相邻的方格交换位置。例如,以下是一个八数码难题的初始状态和目标状态:
1 | |
八数码难题最早出现在19世纪末期,当时它被称为“九宫格问题”,是由美国的一位数学家Sam Loyd发明的。他将数字1到8排列在一个3x3的方格中,留下一个空格,要求将数字重新排列,使得数字从左到右、从上到下依次排列。这个问题在当时引起了很大的轰动,成为了一种流行的智力游戏。
八数码难题在计算机科学中也有着广泛的应用。它是人工智能领域中的一个经典问题,可以用来测试搜索算法的性能和效率。八数码难题也被用来研究人类的思维过程和决策行为。此外,八数码难题还被应用于密码学和安全领域,例如用于生成随机数列和加密算法。
八数码难题的解法可以通过搜索算法来实现。搜索算法是一种通过遍历状态空间来寻找解决问题的方法。在八数码难题中,状态空间是所有可能的状态的集合,每个状态表示为一个3x3的矩阵。搜索算法可以通过遍历状态空间来找到从初始状态到目标状态的路径,即解决方案。
常用的搜索算法包括深度优先算法、广度优先算法、A*算法等。这些算法在八数码难题中的表现不同,具有不同的优缺点。例如,深度优先算法可以实现内存占用小,但可能会陷入局部最优解;广度优先算法可以保证找到最优解,但需要更多的内存空间。
除了搜索算法,还有一些其他的解法可以用来解决八数码难题,例如启发式搜索、模拟退火等。这些方法可以通过引入启发式函数、随机化等技术来提高搜索效率和解决复杂问题。
总之,八数码难题是一个经典的拼图游戏,具有广泛的应用价值。通过搜索算法和其他解法,我们可以找到从初始状态到目标状态的路径,解决这个问题。在计算机科学和人工智能领域,八数码难题是一个重要的研究对象,可以帮助我们更好地理解和应用搜索算法、人工智能和机器学习等技术。
1.1 BSF求解八数码问题
广度优先搜索 (BFS) 算法,从它的名字“广度”开始,通过节点的外边缘发现节点的所有邻居,然后通过它们的外边缘发现前面提到的邻居的未访问邻居,依此类推,直到访问从原始源访问的所有节点(如果还有剩余的未访问节点,我们可以继续并采用另一个原始源,依此类推)。这就是为什么如果边的权重是均匀的,它可以用来找到从一个节点(原始源)到另一个节点的最短路径(如果有的话)。
在八数码难题中,广度优先算法会从初始状态开始,先将所有与初始状态相邻的状态加入队列,然后遍历这些状态相邻的状态,以此类推,直到找到目标状态或者遍历完整个状态空间。
代码如下:
1 | |
输出如下:

1.2 DSF求解八数码问题
深度优先搜索 (DFS) 算法,从其名称“深度”开始,通过其外边缘发现最近发现的节点 x 的未访问邻居。如果节点 x 没有未访问的邻居,则算法回溯以发现节点 x 的节点的未访问邻居(通过其外部边缘),依此类推,直到访问从原始源访问的所有节点(如果还有剩余的未访问节点,我们可以继续并采用另一个原始源,依此类推)。
在八数码难题中,深度优先算法会从初始状态开始,选择一个数字,将其与空格交换位置,然后继续向下搜索,直到找到目标状态或者无法继续为止。如果无法继续,算法会回溯到上一个节点,继续搜索其他方向。
代码如下:
1 | |
输出如下:

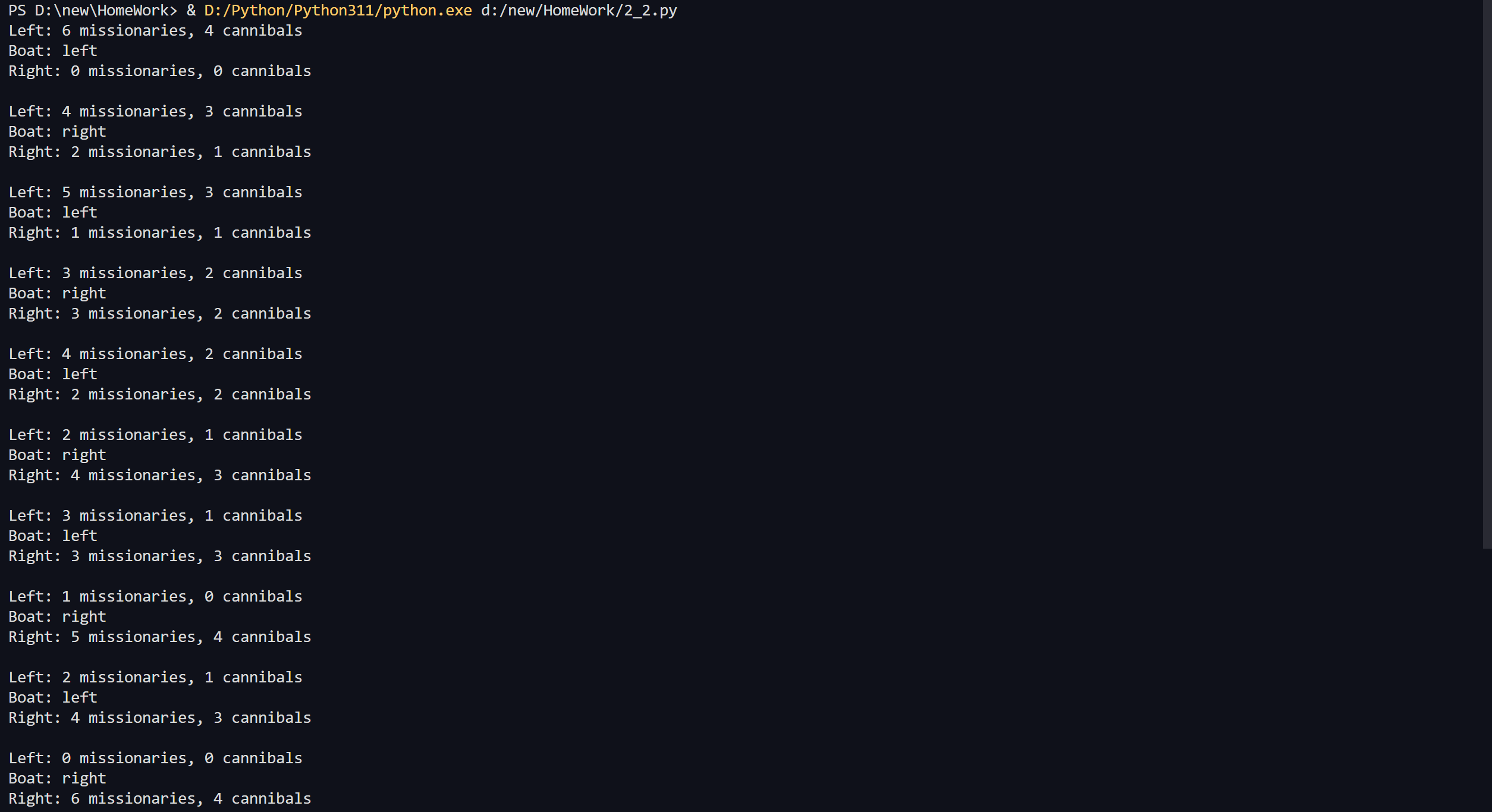
2 分啤酒问题(状态空间搜索问题) 现有8升、5升、3升的容器各一个,均无任何度量标记,其中8升的容器装满啤酒,其他两个为空。要求用上述容器倒来倒去,分成两份4升的啤酒。
代码如下:
1 | |
输出如下:

3 传教士和野人过河问题(启发式搜索算法): 有N个传教士和N个野人来到河边渡河,河岸有一条船,每次至多可供k人乘渡。问传教士为了安全起见,应规划摆渡方案,使得任何时刻,传教士和野人在一起时河两岸及船上的野人数目总是不超过传教士的数目(否则传教士有可能被野人吃掉)。求解传教士和野人从左岸全部摆渡到右岸的过程中,任何时刻传教士和野人在一起时,满足传教士数大于或等于野人数,并且两者人数之和小于k的摆渡方案。
代码如下:
1 | |
输出如下:
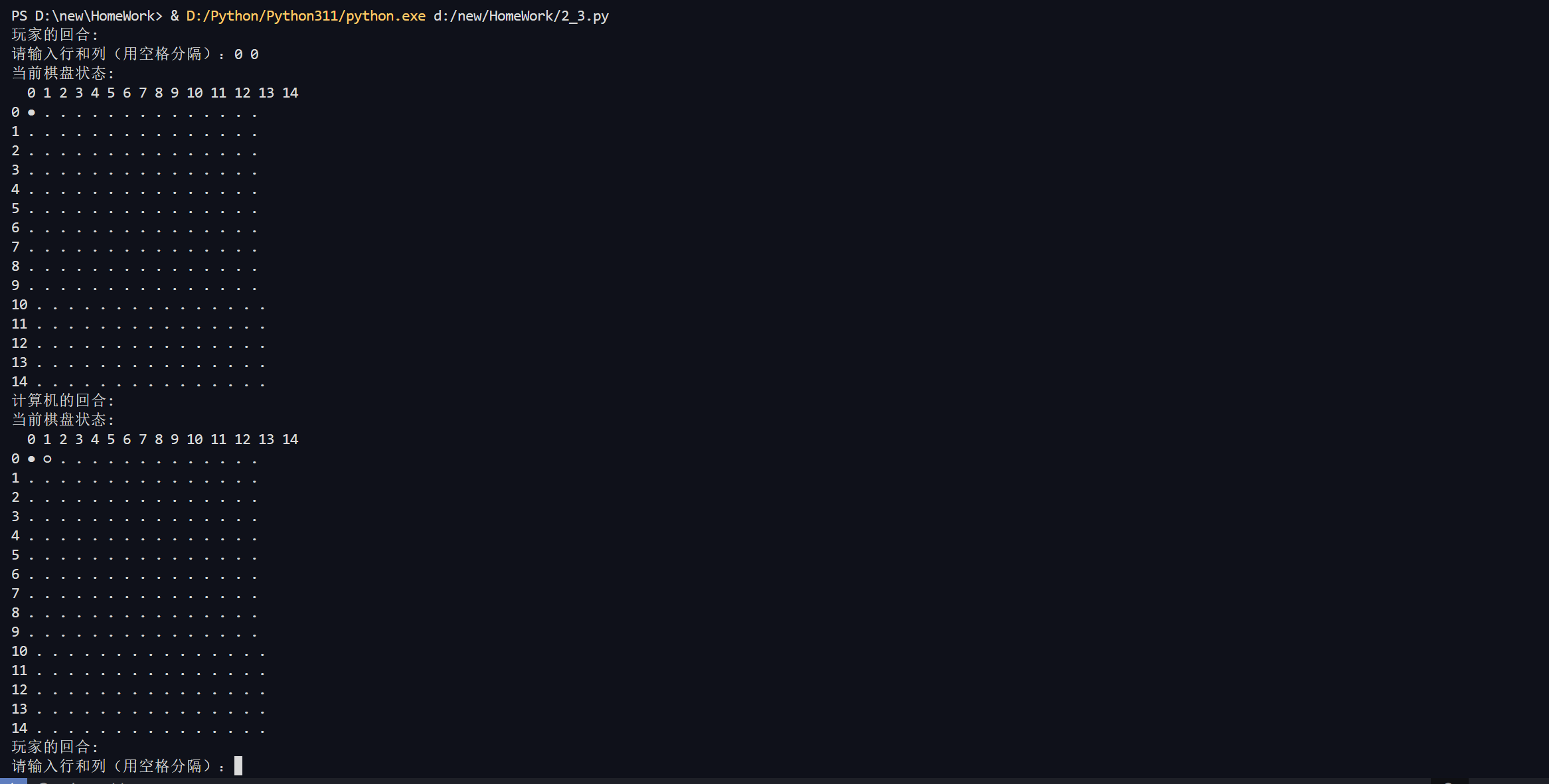
4 人机对战五子棋游戏(博弈搜索α-β剪枝策略) :五子棋的专用棋盘为15路(15╳15),盘面上横竖各15条、平行线、纵横、线路为黑色,构成225个交叉点。游戏规则:先手无限制,在对局开始时,先由执黑棋的一方将一枚棋子落在天元点上,然后由执白棋的一方在黑棋周围的交叉点上落子。此后,由执黑棋的一方在以天元为中心的25个交叉点的范围内,下盘面的第三手棋。然后由执白棋的一方应手,即下盘面的第四手棋。以后如此轮流落子,直到某一方首先在棋盘的直线、横线或斜线上形成连续5子或5子以上,则该方就算获胜。
代码如下:
1 | |
输出如下:
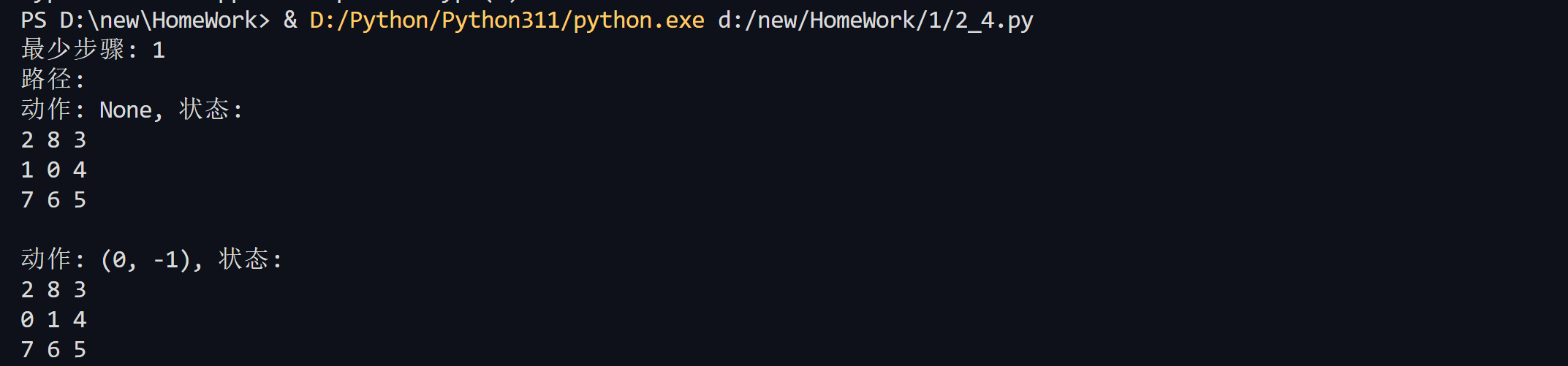
5 求解八数码问题(启发式搜索)在3×3的方格棋盘上,摆放着1到8这八个数码,有1个方格是空的,其初始状态如图所示,要求对空格执行空格左移、空格右移、空格上移和空格下移这四个操作使得棋盘从初始状态到目标状态。目标:求出从初始状态到目标状态的最少步骤和路径(解法)

AStar算法是一种启发式搜索算法,它通过引入启发式函数来评估每个状态的价值。启发式函数是一个估计函数,用来估计从当前状态到目标状态的距离。AStar算法将启发式函数的估计值和已经走过的路径的代价相结合,得到每个状态的价值,从而选择最优的路径。
AStar算法的基本思想是:从初始状态开始,计算每个状态的价值,并选择价值最小的状态作为下一步的目标。在计算状态的价值时,A算法将已经走过的路径的代价和启发式函数的估计值相结合,得到状态的总价值。具体地,A*算法使用以下公式计算状态的总价值: f(n) = g(n) + h(n) 其中,f(n)表示状态n的总价值,g(n)表示从初始状态到状态n的代价,h(n)表示从状态n到目标状态的估计代价。
AStar算法通过遍历状态空间,计算每个状态的总价值,并选择总价值最小的状态作为下一步的目标。如果找到了目标状态,算法就停止搜索,输出解决方案。如果遍历完整个状态空间,仍然没有找到目标状态,算法就停止搜索,输出无解。
AStar算法解决八数码难题的代码如下
1 | |
输出如下: